Learning NLP: Text Similarity Analysis
Explore Similarity Search techniques. Learn practical methods for setting up an NLP pipeline for a similar movie recommendation system.

Have you ever read a book and wanted a similar book? After seeing a great film, you want to see more of them. Can a system do this for me so I don't have to hunt for it? Then I learned about NLP's Similarity Search. With this, we may locate related books, articles, films, and more. We can try something practical around this to see how powerful it is. We can try searching for similar movies from a movie dataset to understand its working.
Find similar movies from a dataset
Set up a colab notebook and follow through the steps.
Install the movie dataset from here and upload it to colab.

Preparation
Initialize the dataset. Remove null values.
import pandas as pd data = pd.read_csv('tmdb_5000_movies.csv') data.head(10) # Let's also take care of the null values present in the data data.fillna('', inplace = True)

We are only interested in original_title and overview columns. We will use the overview for the similarity search process.
Preprocessing
from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer import re nltk.download('wordnet') STOPWORDS = stopwords.words('english') lemmatizer = WordNetLemmatizer() def process_text(text): text = re.sub(r'[^a-zA-Z\s]', '', text) text = text.lower().strip() text = " ".join([word for word in str(text).split() if word not in STOPWORDS]) text = " ".join([lemmatizer.lemmatize(word) for word in text.split()]) return text
In the above step, we applied stopword removal and lemmatization using Wordnet. Stop word removal is used for removing connecting words like is, was, the, etc. Wordnet is used to find out the meaning of words. The next step is applying the process_text function to the overview column.
data['processed_overview'] = data['overview'].map(process_text) # Also, we shall select the top 4 columns for our problem statement data = data[['title', 'overview', 'processed_overview', 'tagline']]
CountVectorizer and Similarity Matrix
The next step is creating a document-term matrix.
# First let us get the processed data data_list = data['processed_overview'].to_list() from sklearn.feature_extraction.text import CountVectorizer count_vect = CountVectorizer(min_df = 0., max_df = 1.) count_vect_matrix = count_vect.fit_transform(data_list) count_vect_matrix.shape # Output - (4803, 20449)
create a similarity matrix using sklearn's cosine_similarity. (More about cosine similarity and other similarity algorithms in the below sections)
from sklearn.metrics.pairwise import cosine_similarity count_doc_sim = cosine_similarity(count_vect_matrix) # Let us create a dataframe out of this matrix for easy retrieval of data count_doc_sim_df = pd.DataFrame(count_doc_sim) count_doc_sim_df.head()

This DataFrame contains pairwise similarity scores between the movies. Each cell (i, j) in the DataFrame represents the similarity score between the i-th and j-th documents
Getting an index from the dataset for a movie title
movies = data['title'].to_list() movie_idx = movies.index("The Dark Knight Rises") Movie_idx # output: 3
Getting the specific row from the dataframe
movie_similarities = count_doc_sim_df.iloc[movie_idx].valuesA similar_movie_idxs = np.argsort(-movie_similarities)[1:6] similar_movie_idxs # output:array([ 299, 1359, 65, 428, 2507])
Finding the similar movies (top 5)
similar_movies = [] for i in similar_movie_idxs: similar_movies.append(movies[i]) Similar_movies

Here is my colab code for setting this up. here Let's see what are algorithms available for similarity search.
Document Similarity Algorithms
Cosine Similarity
Cosine similarity is used to find the similarity between two vectors in space by calculating the cosine angle between them. In the simplest terms, it helps us understand the relationship between two elements by looking at the "direction" they are pointing in. It's widely used in applications like natural language processing (NLP), search algorithms, and recommendation systems.

Jaccard Coefficient
The Jaccard similarity index (sometimes called the Jaccard similarity coefficient) compares members for two sets to see which members are shared and which are distinct. It's a measure of similarity for the two sets of data, with a range from 0% to 100%. The higher the percentage, the more similar the two texts

Manhattan Distance
Distance between two points in an n- n-dimensional space, is used to calculate the similarity between two documents, using their vector representations. The vector representations are created using the TF-IDF vectorization method, similar to the cosine similarity metric.
Named after the pathways in Manhattan where the streets are straight and intersect at right angles, this method is used to calculate the similarity between two documents based on their vector representations, by summing the absolute values of the differences between the values at their respective coordinates.
If documents were encoded as vectors (x1,y1) & (x2,y2). In that case,
Manhattan Distance = |x1-x2|+|y1-y2|
i.e. sum of absolute values of differences of values in corresponding axes.
Manhattan Distance is unaffected by the length of the documents. However, it may not be as accurate as other methods.
Euclidean Distance
Distance between two points in an n- n-dimensional space, is used to calculate the similarity between two documents, using their vector representations. The vector representations are created using the TF-IDF vectorization method, similar to the cosine similarity metric

Word Mover's Distance(WMD)
An advanced technique for measuring Document Similarity. Word Mover's Distance (WMD), suggests that distances between embedded word vectors are to some degree semantically meaningful. It utilizes this property of word vector embeddings and treats text documents as a weighted point cloud of embedded words. The distance between two text documents A and B is calculated by the minimum cumulative distance that words from the text document 'A' need to travel to match exactly the point cloud of text document 'B'.

Use of cases for Vector Similarity Search
Recommendation Systems
The recommendation systems that we see in our day-to-day lives are made using similarity search methods. They represent users as vectors, find similar types of users, and provide personalized recommendations.

For example, when we want to recommend an item to a user, we use the user ID and its vector to check which item vectors in the Faiss engine have the closest Euclidean distance to the user's vector. Faiss is developed by Facebook. It provides multiple vector retrieval modes. It has an excellent performance and is used in the similarity search.
Anomaly Detection
Similarity search is utilized in anomaly detection by comparing the vectors to a normal distribution. We can detect similar items from it. Deviations from the majority can be considered anomalies. Example detecting fraudulent transactions, network intrusions, or equipment failures.
Social Network Analysis
It's used in social network analysis to find similar individuals based on their social connections. They represent individuals as vectors to measure their similarity. This can be used to find influential users and communities, or provide suggestions lists like "people whom you may know".
By representing documents, articles, or web pages as vectors, similarity search enables efficient retrieval of relevant content based on their similarity to a query vector. This is useful in news recommendations, content filtering, or search engines.
In the next section, we will discuss briefly parts we left out in the practical session.
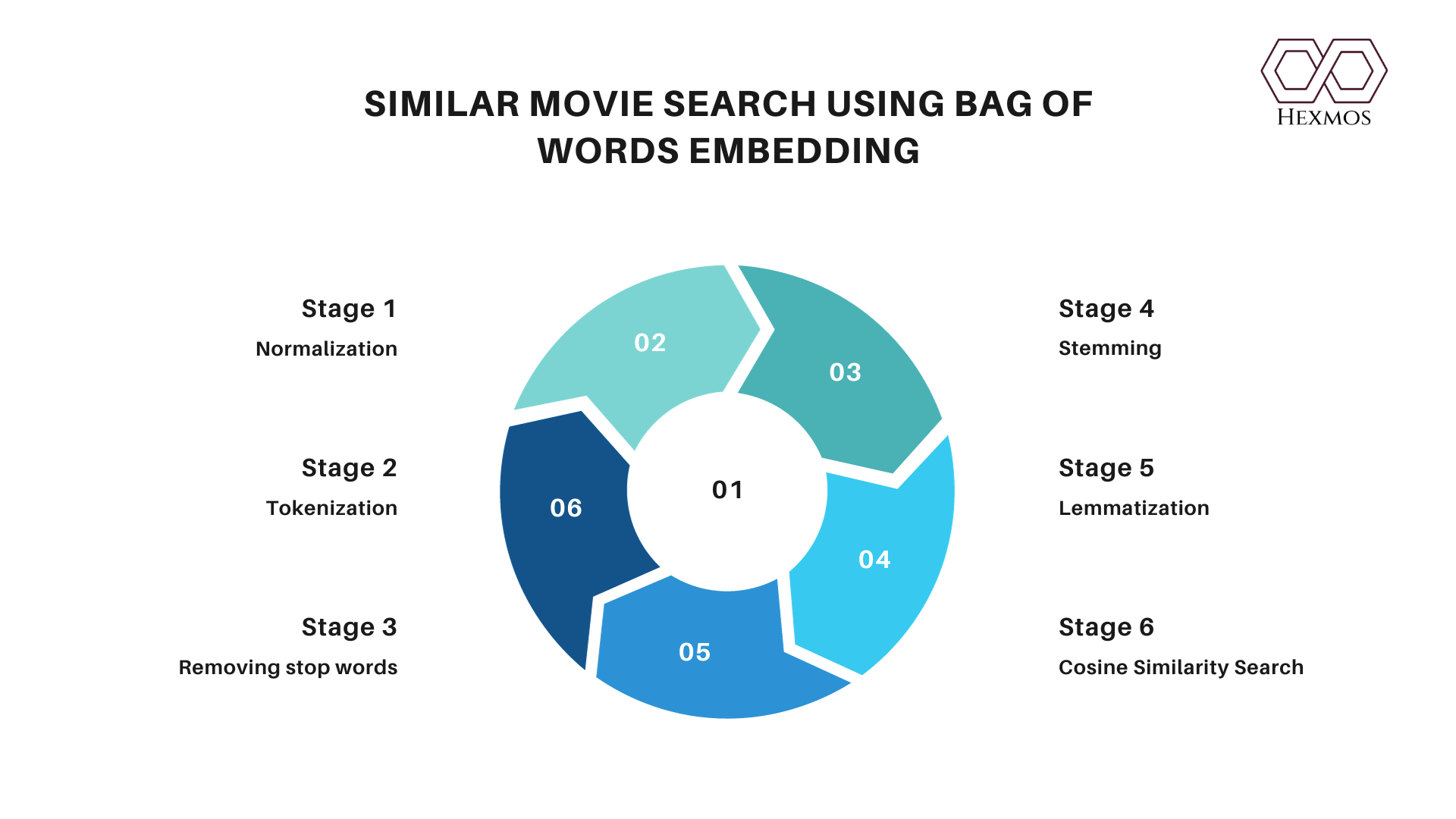
Steps in Similarity Search Preprocessing
Normalization: transforming the text into lowercase and removing all the special characters and punctuations. It ensures uniformity and eliminates case-based variations. Helps in better tokenization.
Tokenization: getting the normalized text and splitting it into a list of tokens. In the example above we are splitting text into individual words.
Removing stop words: stop words are the words that are most commonly used in a language and do not add much meaning to the text. Some examples are the words 'the', 'a', 'will', etc. This helps in reducing noise and improving efficiency in text analysis.
Stemming: aims to reduce words to their root or base form. Sometimes the resulting stem might not always be a valid word.
Examples:Words like "running" and "runs" might be stemmed to "run,".
Lemmatization: In stemming, a part of the word is just chopped off at the tail end to arrive at the stem of the word. We don't actually know the meaning of the word in the language it belongs to. In lemmatization, the algorithms do have this knowledge. In Lemmatization we refer to a dictionary to understand the meaning of the word before reducing it to its root word, or lemma. Examples: "is, was, were" become "be".
Conclusion
This concludes our explorations on nlp similarity search. We came across a lot of NLP tricks. We got insights on getting a basic NLP pipeline going. We learned some techniques in Similarity search. If you find this article useful do sign up for the newsletter. Thanks for reading.





